| Self | 您所在的位置:网站首页 › self-paced visit › Self |
Self
|
前言 Self-paced Co-training发表在icml2017,是马凡师兄还在西安交通大学的时候跟着孟德宇老师做的。本文主要从code(见文末引用)角度对这篇文章进行解析,但考虑到讲code不能脱离文章,所以也会对文章进行简要回顾。 文章简要回顾Co-training理解。最早由Blum he Mitchell在1998年提出(见Combining labeled and unlabeled data with co-training),是一种常见的半监督学习方法。参考[2]的说法,co-training核心就是利用少量已标记样本,通过两个(或多个)model/view去学习。利用多个model/view的(中间)训练结果对未标记样本进行交替预测,挑选出most confidently的样本加入到已标记样本阵营,然后再重复上述过程,直到收敛条件达到为止。co-training目前主要存在两种方法:single-view 和 multi-view。最开始提出的是multi-view,就是对特征进行拆分,使用相同的模型,来保证模型间的差异性。后来论证了single-view方法,也就是采用不同种类的模型,但是采用全部特征,也是可以的。基于后一种方法,好多开始做集成方法,采用boosting方式,加入更多分类器,当然也是可以同时做特征的采样。本文的insight。本文的insight还是很震撼的。传统的cotraining方法通过交替训练多个model/view生产pseudo-label,从而扩充训练集。这里就存在一个问题:模型在迭代前期,生产的pseudo-label很多都是错误的,这些错误的pseudo-label在后期的模型训练中不停地被利用,从而干扰了模型的训练。那能不能解决这一问题呢?这篇文章就是朝着这个方向努力的。他可以做到,动态的选择sample,动态选择具有draw with replacement的特性,从而解决了以前一次选择,终身就不能逃离的困境。给出答案前,需要引入孟德宇老师另一重要的工作--self-paced learning。这里简单对Self-paced Learning进行介绍,想深入研究的可以看下孟老师的主页。我们在求解机器学习模型时,通常有一个目标函数,一般就是模型对标注样本的损失函数。但是我们知道,不可能存在完美的标注样本,在一些情况下,这些标注的样本可能本身就是错误标注的。这时就需要把这些样本在损失函数的计算中去掉(当然Self-paced Learning的另一种解释就是模型训练遵循easy to complex的形式)。怎么做到呢?这时就要发挥数学的作用了。公式(1)给出Self-paced Learning通用形式。我们把重点放在第一项上,观察可以发现,我们控制 \mathit{v}_i 的取值来控制当前样本对 (\mathbf{x}_i,y) 对目标函数的贡献量。极端情况 \mathit{v}_i 全为1的时候,就是传统的损失函数。某些情况为0的时候,这部分样本就不会纳入计算,全为0的话,目标函数就无意义了(当然一般不存在这种情况)。怎么去控制 \mathit{v}_i 的取值呢,就是第二项的作用了。也就是说,我们在计算Loss的时候,可以引入一个额外的项,这个额外的项与损失函数无关,但可以起到控制样本贡献的作用。关于第二项的具体形式以及各种变种,可以参考文章[3]。 (1)这里多说几句, \mathit{v}_i 的取值与 \lambda 以及损失函数 L 有关。一般称 \lambda 为age,常常作为损失函数 L 的某种上界来控制 \mathit{v}_i 的取值。控制损失函数 L 的大小来选择sample的思想其实很常见。大家可以想到object detection领域常用的hard mining,以及最新Kaiming组提到的Focal loss。这里有必要说下Focal loss里得到的一个非常重要的结论。影响物体检测的关键因素是负样本数量太大,这些负样本占总loss比例大,而且多是容易分类的。这些容易分类的loss其实用处不大,但完全忽略会丢失信息,所以引入Focal Loss。对比下这些想法,不知道能不能促生出self-paced Learning新的发现。扯得有点远了...主要工作论述。为了避免co-training在训练过程中引入的错误的pseudo-label数据,本文构建了公式(2)的目标函数。第一项就是传统的损失函数,第二项是正则项。第三项是本文的重点。通过Self-paced Learning对当前生产pseudo-label的样本进行选择。第四项是上面说的用来控制 \mathit{v}_i 的。最后一项也是正则项,用来鼓励view之间的判断的一致性(an unlabeled sample is likely to be labeled correctly or wrongly simultaneously for both views)。求解是常用的Alternative Optimization算法。 (1)这里多说几句, \mathit{v}_i 的取值与 \lambda 以及损失函数 L 有关。一般称 \lambda 为age,常常作为损失函数 L 的某种上界来控制 \mathit{v}_i 的取值。控制损失函数 L 的大小来选择sample的思想其实很常见。大家可以想到object detection领域常用的hard mining,以及最新Kaiming组提到的Focal loss。这里有必要说下Focal loss里得到的一个非常重要的结论。影响物体检测的关键因素是负样本数量太大,这些负样本占总loss比例大,而且多是容易分类的。这些容易分类的loss其实用处不大,但完全忽略会丢失信息,所以引入Focal Loss。对比下这些想法,不知道能不能促生出self-paced Learning新的发现。扯得有点远了...主要工作论述。为了避免co-training在训练过程中引入的错误的pseudo-label数据,本文构建了公式(2)的目标函数。第一项就是传统的损失函数,第二项是正则项。第三项是本文的重点。通过Self-paced Learning对当前生产pseudo-label的样本进行选择。第四项是上面说的用来控制 \mathit{v}_i 的。最后一项也是正则项,用来鼓励view之间的判断的一致性(an unlabeled sample is likely to be labeled correctly or wrongly simultaneously for both views)。求解是常用的Alternative Optimization算法。 (2) (2)文章就讲到这里吧,大家不懂的地方可以看看文章,或者留言一块儿交流。 代码解析这里说下对代码的理解吧。代码改自Facebook Tong Xiao开源的open-reid。整个框架整洁、干练,是个不错的学习资源。框架的详细信息可以参考Sphinx生成的在线文档。由于需要deep learning学习feature,框架需要依赖于PyTorch (version >= 0.2.0)的支持。此外,还调用了umass大学 ALL lab开源metric-learn。这里我们主要以马凡师兄的修改版进行讲解 框架整体架构。$ tree -d -L 2 . ├── docs │ ├── examples │ ├── figures │ ├── notes │ └── _static ├── examples │ └── data ├── reid │ ├── datasets │ ├── evaluation_metrics │ ├── feature_extraction │ ├── loss │ ├── metric_learning │ ├── models │ └── utils └── test ├── datasets ├── evaluation_metrics ├── feature_extraction ├── loss ├── models └── utils框架的主要内容在reid folder下,examples folder下给出了一些框架的实际用例(spaco.py就是论文的实现代码)。docs和test下分别是Sphinx文档和test用例。 下面我们从主函数入手,对论文的实现代码给出说明。 代码详细解析(examples/spaco.py为入口)。# 82-99行 if __name__ == '__main__': => main(parser.parse_args()) # 主要调用argparse软件包,使程序可以接收命令行传递进来的参数。 # 注意:由于--batch-size需要专门配置,所以在此实现中这项参数并没有应用。p.s. 翻开一看,吓了一跳,上次编辑已经11天前了。当然期间发生了一些事情,还参加了MLA2017。今天先写一部分,明天早上必须完成。立帖为证!!! # 71-74行 def main(args): => dataset = datasets.create(args.dataset, dataset_dir) # 这里我们主要关注74行。 # 由于re-id任务有很多数据集,但它们都以不同的格式存在,所以需要我们把它统一起来。 # 以这个为目的,作者实现了统一的数据层代码(见reid/datasets/)。为了能通过参数 # 值来接触到不同的数据集,作者定义了入口文件reid/datasets/__init__.py,从而 # 统一了数据的获取形式,方式是创建__factory字典,形成string到class的映射。我 # 们重点关注Market1501_STD数据集,这个数据集其实是马凡师兄对照原作Market1501 # 自己加的。为什么不用原作者的,马凡师兄的解释是Market1501的query样本和一般论文 # 的标准测试不一样,其实就是修改了download函数病重载了load函数。 # reid/datasets/Market1501_STD.py # 进入Market1501_STD后,我们看构造函数。构造函数主要是执行download和load函数。 # 首先是download函数,由于有些数据集需要复杂的url parse等操作,所以作者给出url, # 希望你自己下载好了再来执行(当然一些简单的可以在程序里download)。91-118主要是 # 判断文件完整和解压缩。120-151行主要是对文件进行统一命名,并且保存成统一的文件结 # 构。153-163主要保存些数据集的原信息,包括meta.json:数据集名称、相机个数、 # single/multiple(一般涉及tracking) shot。splits.json:trainval/test # 的文件名称(路径)、query以及gallery的文件名称(路径)。 # 对比Market1501.py可以看出,马凡师兄修改了splits.json保存的内容,Market1501.py # 保存的是图片的pid,而马凡师兄保存的是文件名,更详细了些。这个具体的作用,我们后面对比 # 看下。 # 然后是load函数。由于download函数有变化,load函数也需要改变,所以师兄重载了load函数。 # 43-47导入上面保存的splits.json。重要的地方就是传进来的参数num_val,他其实是train/val # split的一个分界点。由于本文关注的半监督学习,所以师兄没有实现train,而是在后续code #(spaco.py 26行)实现了train/untrain的split。untrain就是co-training方法的 # unlabeled的数据集仓库。val和trainval都根据pid从identities全集里取(val_pids是 # trainval_pids的后num_val个数据)。接下来67-74就是为什么师兄重写Market1501.py的 # 原因了。原因在于identities库是以pid索引的,而有些test的pid和query pid相等,导致取 # query数据集时,会误取一些test数据集。 # 以上内容其实把整个dataset包都讲了,其他数据集也是类似的。# 75-80行 model_names = [args.arch1, args.arch2] => args.gamma,args.train_ratio) # 读取model name-方便后面根据名字得到model 和save path-方便后面存log接下来就可以进入code的核心spaco函数了。 # 12-28行 def spaco(...) => num_classes = data.num_trainval_ids # 首先解释下几个参数吧。iter_step就是我们co-training交替迭代的次数。gamma比较重要, # 后面讲。train_ratio就是train/untrain中train的比例,以适应半监督学习。 # 重点讲讲26行split_dataset的实现。实现比较特殊,划分train/untrain时,让每个人的图像 # 在train/untrain中都有出现。具体直接看code就可以。p.s.后面就是文章的重点实现了,今晚先到这里吧。 # 33-40行 add_ratio = 0.5 => pred_y = np.argmax(sum(pred_probs), axis=1) # 这几行其实是第一次co-training迭代,目的是对两个model(比如resnet50,densenet121) # 进行训练。add_ratio参数和pred_probs的意义后面讲,直接看37行。这里遍历num_view, # 分别对网络执行train_predict。咱们看看train_predict,这就需要进入models软件包里。 # reid/models/model_utils.py # 进入train_predict函数后,首先执行131行的train。咱们需要进入函数train去详细了解下。 # 首先执行get_model_by_name,这里其实和dataset包一致,也是为了为多个model提供统一的 # 入口,在reid/models/__init__.py定义了__factory字典,达到由model_name到model的 # 映射。可以看到,在reid/models里原作者实现了一般的model接口。 # 下面我们以reid/models/densenet.py为例,讲讲作者的网络搭建技巧。32行可以看到, # 作者又定义了一个__factory字典,达到由model depth得到model的目的。有趣的是,这些 # 常见的model已经在torchvision里包含了(赞扬一个pytorch)。由于原作者想把densenet # 等网络当做base architecture。所以这里重新实现了forword函数。对比forword函数以及 # 37-62行,可以发现,这里加了一个全连接层,支持固定个数的num_features输出,并映射到 # 类的个数空间里。 # 继续讲解reid/models/model_utils.py的train函数107-110是得到训练网络的数据层和 # 参数,这时,我们会发现spaco.py传入的--batch-size其实没有用。重点讲109行。这里就 # 是对数据进行一些常见的变换了,目的就是达到数据增广的效果。进入 # reid/utils/data/data_process.py 直接看函数get_dataloader。这里重点看26行, # 传入DataLoader的第一个参数Preprocessor,这是一个类,这个类比较特殊的地方就是必 # 须实现__getitem__方法,以便于DataLoader进行数据获取。想深度了解的,其实看看pytorch # 实现的DataLoader,以便于为自己后续开发积累。回到train函数,接下来就是训练网络了 # (函数train_model),这个实现比较简单,大家自己就能看懂。 # 到这里reid/models/model_utils.py里的train函数就讲完了 # 回到train_predict,发现紧接着就是根据上面训练好的网络进行预测。重点看 # reid/models/model_utils.pyde 133行。这里传入untrain data,用训练好的网络对 # untrain data进行预测,以便服务于co-training。 # 下面进入predict_prob进行详细说明。首先是get_feature函数,这个主要涉及untrain data # 的数据封装(创给dataloader),然后把网络的预测拿到。具体怎么拿到的,其实可以看 # torch/nn/modules/module.py里的__call__函数。123-126行就是用softmax把这些 # feature映射到概率空间。最终得到untrain data的概率预测。 # 至此train_predict全部函数讲完。回到主函数的39行这里需要把实现与算法对上,所以贴上算法图  Update vk Update vk Update w Update w Update yk Update yk Algorithm Algorithm上面我们主要讲了1-5步,当我们进入第八步迭代时,查看公式(4)会发现需要通过控制loss \mathbf{L}_k 对 \mathit{v}_k 进行更新。那我们实现上是不是必须先计算loss?答案是否定的,由于公式4的目的在于控制loss大的样本不被选中,loss大对应预测概率低,所以这里不需要计算loss,而是简单的对预测概率进行操作就可以了。有了这样的认识,我们继续进行code讲解就变得容易了。 # 39行 add_ids.append(dp.sel_idx(pred_probs[view], train_data, add_ratio)) # 我们直接跳进dp.sel_idx里。 # 这里我们会发现add_ratio是每次从untrain data添加进train data的比例。这个函数实现 # 也很容易理解。就是根据上面得到的pred_prob,对预测概率进行排序,然后取前面ratio个数据 # 以便加进来,为另一个view下次训练服务。接下来看算法的第9步,这一步的目的是选择最终被拿来当做训练数据的untrain data。45-47的目的是在另一个view对untrain data选择的基础上选择出符合本view model预测效果的数据。方式也是用dp.sel_idx对概率进行排序选择。这里需要注意的是,为了增加最终加入train data的untrain data个数,先对预测概率加了一个gamma,参数的另一个意义就是对照算法的age \lambda 。接着50-53行对train data进行更新,并继续co-training训练。56-63行为下次迭代选择样本服务。 到这里,co-training的算法基本上讲完了。接下来结合code讲讲re-id的评价标准。由于最近才接触re-id,对其评价标准极其不了解,我就查查资料,慢慢讲吧。 评价指标从code层面讲,评价指标引入了metric learning。具体来说就是把算softmax以得到概率之前的logit当做feature,他们的真实label当做监督信息,来训练一个metric。这个metric可以是metric learning领域的任何metric,前文也提到了,作者主要引入了metric-learn开源包。至于为什么把logit当做feature,以及为什么用euclidean distance(code中用的这个,这个就不用metric learning),这个我现在还没想明白。为什么没想明白,是因为训练时用的CrossEntropyLoss,没有涉及两个样本的交互(具体code可见reid/trainers.py,上面没详细讲这里)。 撇开上面的疑问,我们继续看评价指标。主要看reid/evaluators.py evaluate_all函数。 这个函数的输入就是我们计算好的query和gallery的parewise的distmat。这里主要是82行计算map(mean average precision)以及96行计算cmc(Cumulative Matching Characteristics ) score。 mAP(reid/evaluation_metrics/ranking.py 函数mean_ap):101行对distmat的第一维(从0计数)进行排序,得到每个query的距离排序。然后遍历m个query,Filter out the same id and same camera(107-109),调用sklearn.metrics的average_precision_score进行ap计算,最后得到mean ap。我个人的理解average_precision刻画了precision与recall的对应关系,一般recall越大,precision越低。理由在于recall代表ranking序列中正样本的占总正样本的比例,如果选择的样本都是正样本的话,也就是说前面的ranking都是正样本,其实不太符合逻辑,此时对负样本的预测效果就会很差,所以precision比较低。更是详细的可以参考知乎mean average precision(MAP)在计算机视觉中是如何计算和应用的?cmcreid/evaluation_metrics/ranking.py 函数cmc:cmc主要从ranking角度评价re-id model的性能。具体地,给定query,查看相同的gallery在topk的ranking中是否出现。作者给出的文档解释在这。实现角度还是针对distmat的第一维排序(从0计数),得到每个query的距离排序。由于re-id分single shot 和multi shot(tracking),所以评价方式不一样。single shot的实现需要对每个gallery_id sample一个gallery去评判结果是否在ranking中出现。Poster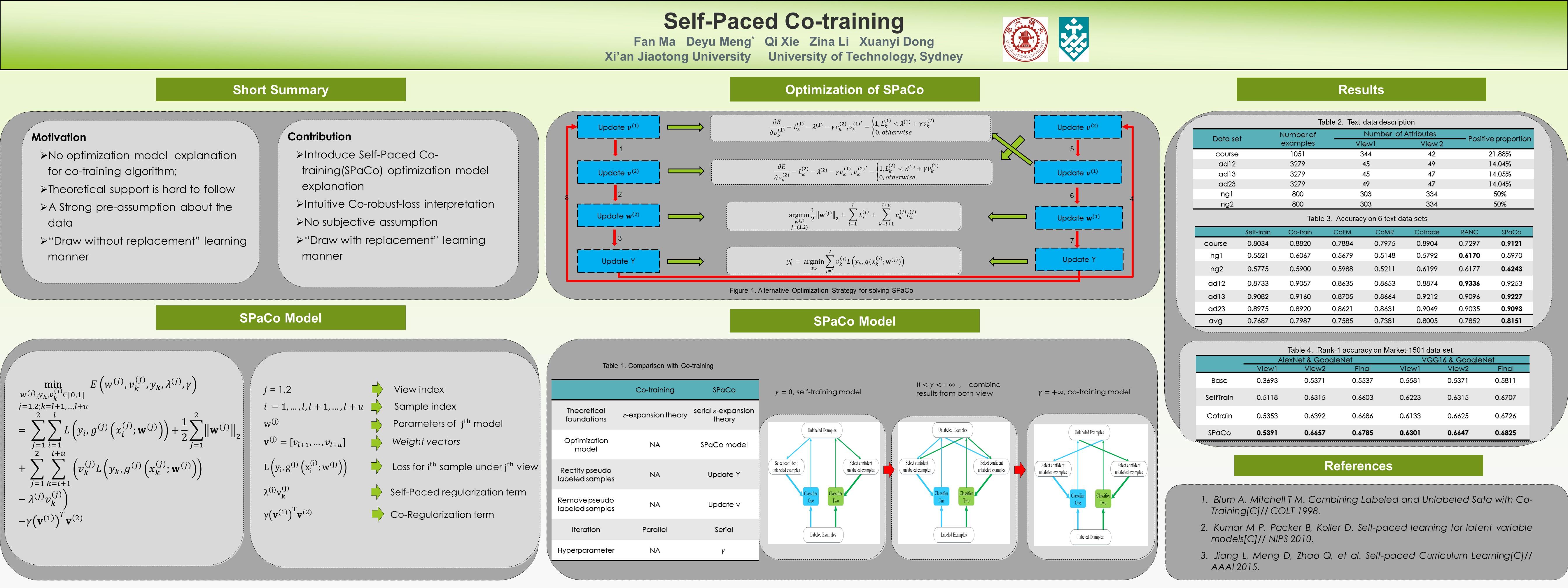 文中的证明 文中的证明这个有时间我来分析下吧。 [1] Fan Ma, Deyu Meng*, Qi Xie, Zina Li, Xuanyi Dong, Self-paced Cotraining, ICML, 2017. [supplementary material][code][github link] [2] Co-training 初探快切入 [3] Lu Jiang, Deyu Meng, Teruko Mitamura, Alexander Hauptmann. Easy Samples First: Self-paced Reranking for Zero-Example Multimedia Search. ACM MM. 2014. Slides. |
【本文地址】